En julio del 2020 Twitter lanzó oficialmente lanueva versión de la API. Esta «V2» tiene como objetivo modernizar el funcionamiento interno de la plataforma y modificar las formas de acceso a la información almacenada en sus servidores. Pero entre las novedades más destacadas, está el acceso especial para académicos, que permite a los investigadores obtener datos históricos de Twitter con gran nivel de precisión y granularidad.
Desde el nacimiento Twitter, en el año 2006, los investigadores han estado usando los datos recopilado de la plataforma para analizar el debate público. Las interacciones y mensajes de los usuarios han demostrado ser de utilidad para entender la opinión pública, las percepciones, y el modo en cómo la sociedad intercambia información haciendo uso de nuevas herramientas y tecnologías. Últimamente, por ejemplo, ha sido de vital importancia para comprender el modo en cómo circula la desinformación. Twitter ha sido consciente de la utilidad de su herramienta para la realización de estudios de carácter sociológico o comunicativo en el marco universitario y científico. Eso, ligado a una política de datos abiertos y accesibilidad —todo lo contrario que Facebook—, han propiciado la aparición de este nivel de acceso.
El acceso para académicos a la API de Twitter
El nuevo acceso para académicos, permite obtener a través de la API gran cantidad de datos, de cualquier momento histórico (desde el nacimiento de Twitter hasta la actualidad), de cualquier cuenta de usuario, hashtag o palabra clave. Actualmente el acceso para académicos tiene los siguientes límites:
- 10 Millones de Tweets mensuales: es el límite de datos que mensualmente puedes recopilar usando una misma clave de acceso. Nada impide que tengas dos, o tres claves de acceso.
- 300 peticiones a la API en una ventana de 15 minutos.
- 500 Tweets por petición a la API.
En resumen, los límites de peticiones (rate limits) actuales permiten recopilar aproximadamente 150.000 tweets en 15 minutos, lo que resulta más que suficiente para la mayoría de las investigaciones. Sin embargo, algunos investigadores que requieren un mayor volúmen, y Twitter está —actualmente— trabajando en accesos «superiores» para investigaciones puntuales.
Capturar datos a través de la nueva API de Twitter utilizando el acceso para académicos
Aquellos quienes han trabajado con datos de Twitter, muy posiblemente en algún momento han hecho uso de la herramienta TCAT —Twitter Capture and Analysis Toolset—, desarrollada en el marco de la Digital Methods Initiative, un grupo de investigación vinculado a la Amsterdam University.
El TCAT ha sido —hasta ahora— la única la única herramienta disponible con interfaz de usuario para la captura de datos de Twitter con una clara orientación a la investigación en el ámbito académico. El TCAT aprovecha el acceso estándar a la API, y captura la información en directo. Tiene tres restricciones importantes:
- Puede capturar el 1% de la actividad total de Twitter, causando una posible pérdida de información cuando se capturan datos de eventos globales o masivos.
- La captura se realiza en tiempo real, con un pequeño «delay» entre la publicación del Tweet y su detección y almacenaje. Esto causa que las métricas de interacción sean inmaduras, al no dejar que el Tweet alcance su zenit.
- Es necesario trabajar con previsión: Twitter captura datos sobre palabras clave previamente declaradas en la herramienta. Es decir: es necesario prever lo que se desea capturar. La herramienta no puede capturar datos previos al inicio de la captura. Esto provoca que perdamos datos si no tenemos capacidad para reaccionar a un evento espontáneo.
Actualmente no existe ninguna herramienta con interfaz de usuario —al mismo nivel que el TCAT— que incorpore o aproveche el nuevo nivel de acceso para académicos. Me consta que algunos grupos de investigación, integrados por desarrolladores informáticos e investigadores, están trabajando en herramientas que permitan explotar este acceso desde una interfaz amigable de escritorio —o webapp—. Con la debida financiación es posible posicionarse como referente en este ámbito, existiendo ahora una ventana de oportunidad.
En los últimos meses he estado trabajando en solitario en una herramienta propia, que funciona sin interfaz de usuario. Esta explota esta característica nueva de la API de Twitter. El software está totalmente disponible en Github bajo licencia GNU —Twitter-API-V2-full-archive-Search-academics—. Es plenamente funcional, pero lamentablemente es necesario tener conocimientos de Python para ponerlo en marcha. Al no tener a mi alrededor ningún maquetador, ni el apoyo de ningún grupo de investigación, al no disponer de recursos económicos ni humanos, no he podido desarrollar este programa de un modo que sea «accesible» para toda la comunidad. Con la debida inversión, podria ser una herramienta extremadamente potente al alcance de cualquier investigador, sin que se requieran conocimientos de programación.
Algunos ejemplos con la nueva API de Twitter
Actualmente la herramienta que os he compartido permite obtener los tweets de:
- Cualquier momento (desde el nacimiento de Twitter)
- El historial completo de cualquier usuario
- Todos los Tweets que contengan un determinado «hashtag»
- Todos los tweets con una determinada palabra clave
Además, estas operaciones de captura se pueden mejorar y refinar usando operadores y boléanos, que ayudan a acotar los datos que se recopilan:
- En unas fechas determinadas o rango de fechas concreto.
- De un determinado usuario o grupo de usuarios.
- Que sean / no sean Retweets.
- Que contengan / no contengan un determinado tipo de medio (foto, video, gifs).
- Que sean / no sean contenido sensible (para +18 años).
- etc…
Con una operación de captura, el software que os comparte permite:
- Obtener un dataset completo con los datos solicitados.
- Una lista de adyacencia para crear una red de co-hashtags (2 o más Hashtags que aparecen juntos).
- Una lista de adyacencia para crear una red de usuarios/hashtags (incluyendo co-menciones).
- Una tabla de aristas + nodos que permite crear un grafo de «co-anotaciones».
Un ejemplo: la «co-annotation Network»
La red de co-anotaciones —co-annotation network— es un tipo de red creada a partir del campo «annotations», que ofrece la nueva API de Twitter. Este campo almacena nombres de lugares, empresas, organismos oficiales, productos y personas. Se genera mediante el reconocimiento automático que realiza Twitter sobre las publicaciones —usando inteligencia artificial, claro—.

Mediante este campo, es posible crear una red que permita visualizar los vínculos entre todos estos elementos. La «co-annotation network» es especialmente útil para analizar rápidamente la conversación y las vinculaciones que se establecen entre diferentes conceptos considerados clave. Facilita enormemente la comprensión del contenido del conjunto de datos y visibiliza los principales ítems de la conversación.
Además, el campo «co-annotation» viene acompañado de otro campo descriptivo, en el que se establece la categoría de cada uno de los elementos detectados en el Tweet, lo que posibilita comprender, más allá del «elemento clave», su tipología y categoría.
En el siguiente grafo, por ejemplo, es posible observar la red de co-anotaciones generada a partir de los Tweets de Pedro Sanchez. En el grafo vemos los lugares (verde), las personas (rosa) y las organizaciones (celeste), así como sus vinculaciones dentro de la conversación.
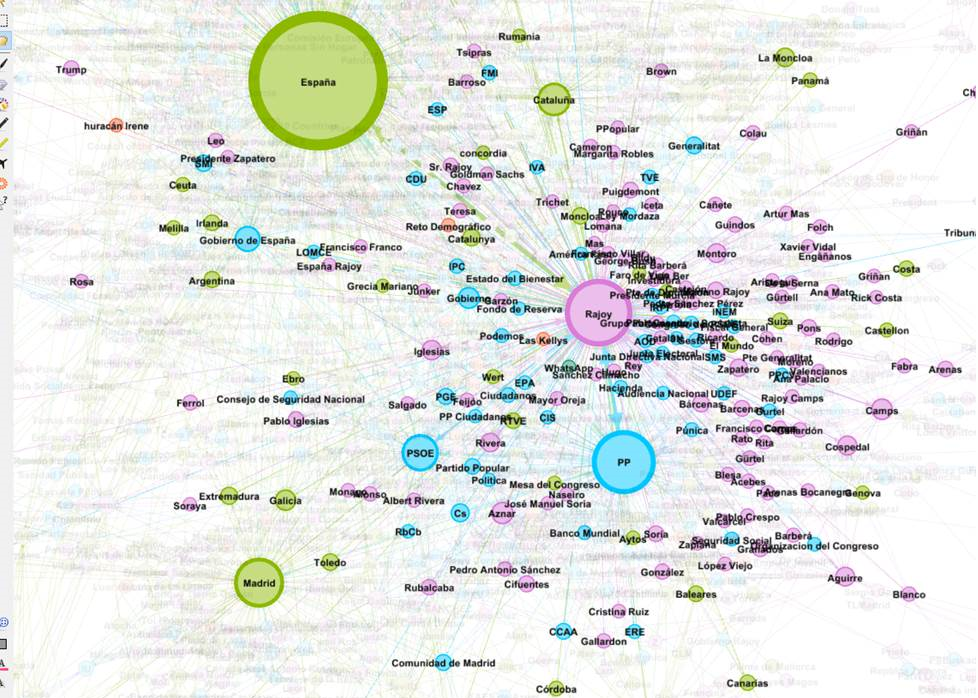
Descarga el detaset completo: Todos los tweets de la cuenta de Pedro Sánchez (hasta mayo del 2021) y los correspondientes archivos de red, para generar las visualizaciones con Gephi.
Un futuro incierto para el TCAT
Los nuevos accesos para investigadores permiten recoger toda la información a posteriori, cuando la actividad sobre un evento ha finalizado y las métricas se han consolidado y estabilizado. La nueva metodología de trabajo también permite delimitar el periodo recolección, acotar a ciertos usuarios, palabras clave, obtener la totalidad de la información disponible y con mayor profundidad, eliminando sesgos que pueden anular la validez de la investigación. Esto deja al TCAT en una posición de desventaja, y será necesario ver cómo avanza la herramienta para incorporar todas estas nuevas funcionalidades.